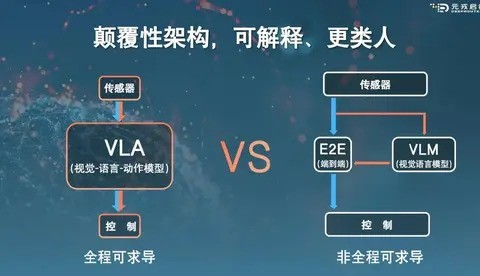
VLA(视觉语言动作模型)是一种融合了视觉语言模型、端到端E2E决策能力和全局上下文理解与类人推理能力的技术。它有望在未来两年内改变智驾市场的格局。
对于自动驾驶来说,VLA可以从传感器数据中提取环境信息,并借助语言模型理解和生成可解释的决策过程。最终,VLA将多模态信息转化为具体的驾驶操作指令。相比传统的VLM和端到端方案,VLA解决了突发情况下反应迟缓、缺乏信任解释力以及应对复杂场景时缺乏全局性问题等问题。这将大大提升城区NOA(智能导航辅助系统)的普及率,并拉开头部车企在智驾体验方面的差距。
要使VLA技术得以落地,需要具备三个要素:技术积累、数据规模和算力支持。只有高阶智能驾驶车型积累了大量驾驶数据,才能为VLA的训练和优化奠定坚实基础。同时,高性能芯片的量产上车也为云端训练和本地化部署提供了强大的算力保障。
然而,在目前市场上使用VLA智驾的车企仍较为少数。由于部署高性能芯片和VLA模型的长期投入非常高,中小型玩家在后发追赶方面可能会遇到更多困难。因此,最早一批采用VLA智驾的玩家很可能是那些具有足够资金和技术实力的企业。
总体而言,VLA技术的发展前景非常广阔。随着技术的不断成熟和应用范围的扩大,我们有理由相信未来智能驾驶将变得更加安全可靠、智能化程度也将得到显著提升。
本文属于原创文章,如若转载,请注明来源:智能驾驶VLA技术进展:未来两年将颠覆行业格局https://auto.zol.com.cn/944/9449722.html

























































































